Overview
- Actually, i attended hadoop summit 2016 - tokyo at last month. So i am going to review some of the talks that i heard. Also you can download slides and watch the videos from youtube.
- slides
- youtube
- Unfortunately, just keynote videos were uploaded now. But i think each session’s video will be uploaded soon.
- This article is about ‘Path to 400M Members: LinkedIn’s Data Powered Journey’. But this article covers only the backend infrastructure at LinkedIn, especially DALI (A Data Access Layer for LinkedIn).
LinkedIn’s Data Powered Journey
Speakers of this talk are Xin Fu (data scientist), and Carl Steinbach (data engineer). You can download the slide. Unfortunately, video is not uploaded yet. They introduced how the number of LinkedIn’s users was growing fast, and how they overcome challenges. One of the speaker Xin Fu introduced how data scientist works at LinkedIn, and what was the challenges, and how they overcome. And another speaker Carl Steinbach introduced DALI which i am going to review at this article. Also he already introduced DALI before at another hadoop summit. I have curious about DALI more, because i also have similar consideration and challenges at my work, even though my platform is not about data infrastructure. So i watched that video and slide. Actually DALI is not an open source. So i gonna focus on conceptual design and architecture.
Motivation of DALI
- Hadoop at LinkedIn
- 10 clusters
- 10,000 nodes
- 1,000 users
- Scaling Hardware Infrastructure is hard.
- Scaling Human Infrastructure is harder.
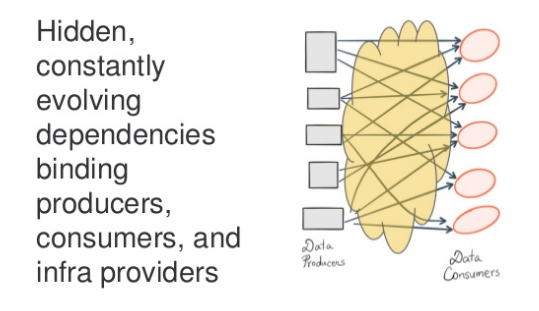
- Data Consumers
- What data is available, and who produces it?
- Where is the data located? (cluster, path)
- How is the data partitioned? (logical -> physical)
- How do i read the data? (format)
- Data Producers
- Change Management (who depends on this dataset?)
- Public versus Private APIs
- Schemas are too weak
- Infra Providers
- Lots of optimizations are impossible.
- Lots of redundant code paths to support.
- Separating logical and physical concerns is the key.

Dataset API
- Dali dataset api (catalog service) support logical dataset ‘Table’ instead of physical location, schema, partition. This idea is like Hive metastore.
- Table is not enough.
- Structural transformations (flattening and nesting)
- Nesting data is inconvenient to use, so flattening version is needed
- Actually, data is same. The difference is shape.
- Materializing Table is inefficient.
- Multiplexing and Demultiplexing datas or event types
- One example is PVE (page view event), which is click stream information.
- PVE is actually union of hundreds of different event types.
- Most queries is about filtering one or a few specific event types. Most of data are filtering out. They have to scan through entire thing. It is very inefficient.
- Some other use case is that from the start, move one event type to another event type and applying transformation. If you want to demultiplex PVE event to separate event types, it is very inefficient for them to manage. Every time adding a new event type, they have to update workflow.
- Patching bad data
- Backward incompatible changes
- removing a field
- narrowing an existing field
- Code reuse
- Structural transformations (flattening and nesting)
- requirements
- Ability to decouple the API from the dataset.
- Producer control over managing API.
- Tooling and process to support safe evolution of these APIs.
DALI View
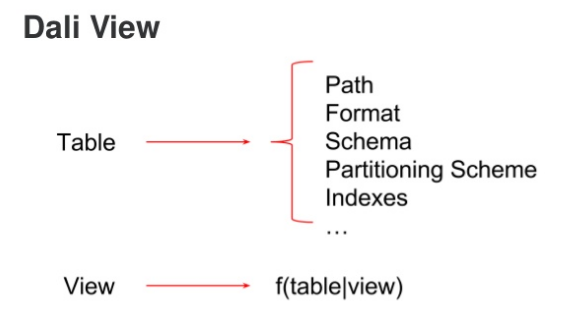
- Most traditional database’s view is materialized.
- Hive view is virtual. When you select from view, behind the scene hive is rewriting view queries.
- DALI view takes this idea.
- Embedding Hive query compiler and execution engine to Data Adapters which work with pig, spark, scalding..
- Adding a couple of additional restrictions. DALI views only allow projections, filters. Not allowing joins and aggregations.
Versioning
- incremental upgrades
- If couple hundred people collaborate on a complicated data pipeline, cannot push force to upgrade simultaneously.
Managing views as Gradle artifacts.
- Git is the source of view definitions.
- 1:1 mapping between views and published artifacts.
Contract Law for Datasets
- Arrtibutes
- Easy to find
- Easy to understand
- Eash to change
- Express contracts as logical constraints against the fields of a view.
- Make the contract easy to find by storing it in the view’s Git repo.
- Contract Negotiation
- Data producer (view owner) controls the ACL on the view repo.
- Data consumer requests a contract change via ReviewBoard reqeust.
- View owner either accepts or rejects the pull request.
- if accepted, view version is bumped to notify downstream consumers.
- if rejected, consumer still has the option of committing the constraints to their own repo.
DALI Implementation Details
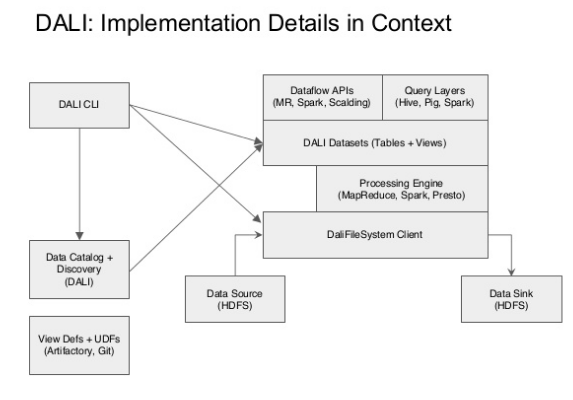
Why DALI?
- Consumers
- Stable
- Predictable
- Discoverable
- Producers
- Explicit, manageable contracts with consumers
- Familiar process for modifying existing contracts
- Infra Providers
- Freedom to optimize
- Flow portability -> DR, multi-DC scheduling